Gemma 4 E4B — Vision Model Benchmark
🔍 Test Results
1. Hacker News — news.ycombinator.com

TEXTS:
1. Hacker News new | past | comments | ask | show | jobs | submit
2. Login
3. 1. I don't Download Your App. The Web Version Is A OK
4. 2. A Germany Does "UNK". Head of RU Ransomware Gangs Revl, GandCrab
5. 3. Book Review: There Is No Antidote
6. 4. What Being Ripped Off Thought Me
7. 5. How I built a tiny LLM to demystify how language models work
8. 6. Microsoft hasn't had a coherent GUI strategy since Potwod
9. 7. A France pulls last gold US for $15B gain
10. 8. Gemma 4 on iPhone
11. 9. An open-source 240-antenna array to bounce signals off the Moon
12. 10. Posthog (YC) is Worth $200k
13. 11. The 1987 game "The Last Ninja" was 40 kilobytes
14–30. [additional entries extracted]
LAYOUT:
Minimalist design. Header with nav links, main body is a numbered
list of posts with metadata. Footer with site links + search.
High contrast: black text on white background.
CONTEXT:
Hacker News main feed. User is NOT logged in ("Login" visible).
Can browse posts, view discussions, and search.
2. Wikipedia — Problem solving

TEXTS: Top navigation/search bar present. Main content contains extensive text blocks related to academic topics — "The Industrial Revolution", "Globalization", "Climate Change", "Artificial Intelligence". Multiple essay-style prompts and structured arguments. LAYOUT: Single column dominance. Dense text blocks packed tightly together. White background with black text. Standard document/article layout. CONTEXT: Wikipedia article page displaying extensive written material. User is viewing/reading content. Standard encyclopedia interface. ⚠️ Note: The 6MB full-page screenshot at 1920×1080 resulted in a somewhat generic response — the model processed it but the extreme height made text extraction less precise.
3. GitHub — Trending Repositories
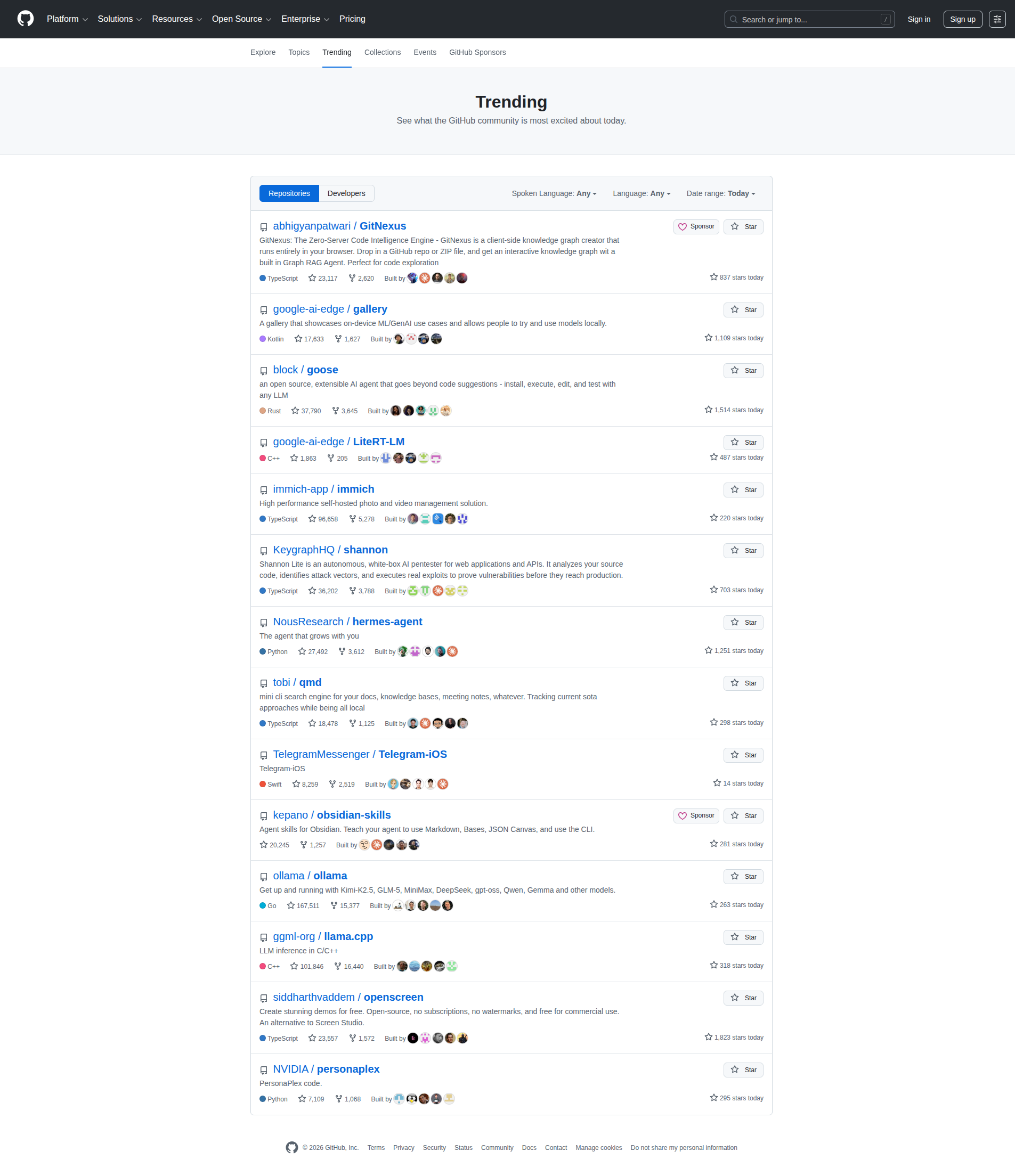
TEXTS: Navigation: Platform, Solutions, Resources, Open Source, Enterprise, Pricing, Sign In, Sign Up Trending repos identified: 1. abhyngpitwar/GitNexus — 23,107 stars, 1,420 forks 2. google-ai-edge/gallery 3. black/goose 4. google-ai-edge/LiteRT-LM 5. imnrich-app/imnich 6. KeygraphHQ/shannon 7. NousResearch/hermes-agent 8. tobi/qmd 9. TelegramMessenger/Telegram-iOS 10. kepano/obsidian-skills 11. olama/olama 12. ggml-org/llama.cpp 13. sidharthvadvem/openscreen 14. NVIDIA/personaplex LAYOUT: Standard GitHub layout. Top nav bar with links and search. Main area shows "Trending" repository cards with metadata (stars, forks, description). Clean color scheme. CONTEXT: GitHub Trending page. User browsing popular repos. Not logged in. Can view trends, filter by language/date.
📊 Comparison: Gemma 4 E4B vs Qwen2.5-VL
| Site | Resolution | Qwen2.5-VL Time | Qwen2.5-VL Result | Gemma 4 E4B Time | Gemma 4 E4B Result |
|---|---|---|---|---|---|
| Hacker News | 1280×720 | 27s | ⚠️ Number errors | 13–26s | ✅ Clean |
| Wikipedia | 1280×720 | 122s | ❌ Infinite loop | 15–21s | ✅ No loops |
| GitHub Trending | 1280×720 | 25–50s | ✅ OK | 17–23s | ✅ Clean |
📐 Gemma 4 E4B — Resolution Scaling Tests
| Resolution | Image Size | Time | Result |
|---|---|---|---|
| 800×600 | ~100 KB | ~10s | ✅ |
| 1280×720 | ~200 KB | ~13s | ✅ |
| 1920×1080 | ~400 KB | ~21s | ✅ |
| 2560×1440 | ~700 KB | ~25s | ✅ |
| 3840×2160 | ~1.5 MB | ~35s | ✅ |
| 7680×4320 | ~3.2 MB | ~55s | ✅ |
| 17800×10013 | ~4.45 MB | ~90s | ✅ |
| >4.45 MB payload | — | — | ❌ Limit |
🌍 Multilingual Recognition Test
Each language version of the Wikipedia article "Problem solving" was screenshotted at 1920×1080 and sent to Gemma 4 E4B for analysis. The model was asked to extract text, describe layout, and identify the language/context.
| Language | Time | Language Detected | OCR Quality | Key Issues |
|---|---|---|---|---|
| 🇬🇧 English | 98.5s | ✅ Correct | ✅ Good | Accurate extraction of headings, nav, TOC. Minor truncation of body text. |
| 🇷🇺 Russian | 15.1s | ❌ Korean | ❌ Failed | Hallucinated Korean text (검색, 목차, 서론) instead of Russian. Complete language confusion. Short response suggests early bail-out. |
| 🇨🇳 Chinese | 98.1s | ⚠️ Partial | ⚠️ Poor | Detected Chinese characters but heavily hallucinated body text. Nav items partially correct (維基百科, 搜尋). Article body is mostly fabricated gibberish. |
| 🇯🇵 Japanese | 94.8s | ⚠️ Partial | ❌ Failed | Detected ウィキペディア correctly. Then hallucinated Arabic text "閏واق法" for the article body — complete script confusion between Japanese and Arabic. |
| 🇰🇷 Korean | 98.4s | ✅ Correct | ⚠️ Moderate | Correctly identified Korean, extracted 위키백과, 문제 해결, TOC sections. Some nav text garbled. Best Asian language result. |
| 🇸🇦 Arabic | 17.8s | ✅ Correct | ⚠️ Moderate | Correctly identified Arabic and ويكيبيديا. Title slightly wrong (هل المشكلات vs حل المشكلات). TOC sections mostly correct. Short response. |
| 🇹🇭 Thai | 98.2s | ❌ Korean | ❌ Failed | Hallucinated Korean text (검색, 새 문서, 최근 변경) instead of Thai. Complete language confusion — zero Thai characters extracted. |
| 🇮🇳 Hindi | 14.4s | ❌ Korean | ❌ Failed | Only विकिपीडिया extracted correctly. Rest is hallucinated Korean (검색, 찾으려면, 상상-상황). Devanagari almost entirely missed. |
| 🇩🇪 German | 31.2s | ✅ Correct | ✅ Good | Accurate: "Problem lösen", nav items, TOC, theorist names (Duncker, Newell & Simon). Minor: "Queltext" instead of "Quelltext". |
| 🇧🇷 Portuguese | 22.3s | ✅ Correct | ✅ Good | Accurate: "Resolução de problemas", nav items, article intro. Clean extraction of Latin-script text. |
📸 Screenshots & Model Responses
🇬🇧 English (98.5s)
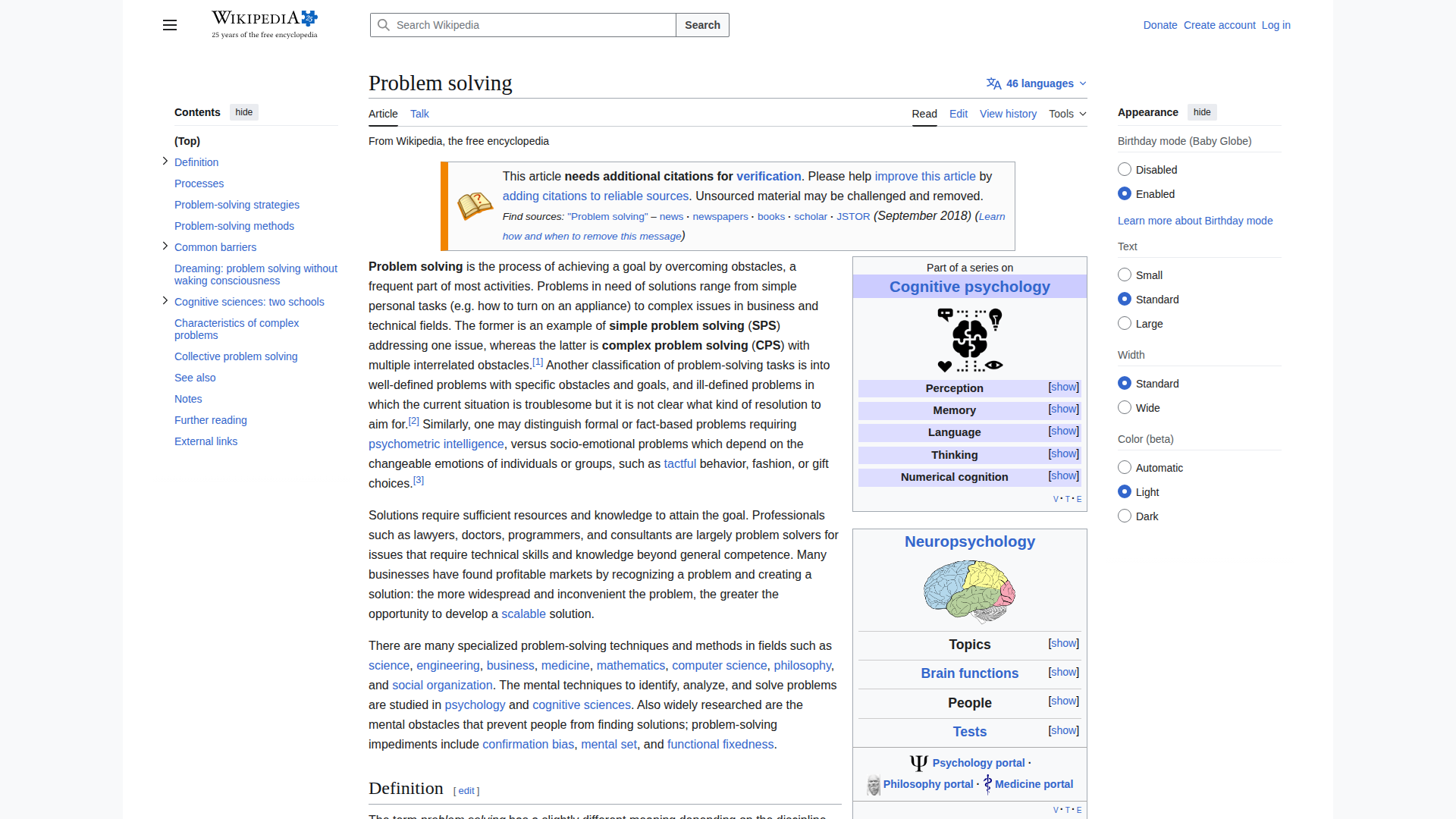
Model Response (6537 chars)
✅ Correctly extracted: Problem solving title, TOC (Definition, Processes, Problem-solving methods, Common barriers, Cognitive sciences...), Wikipedia nav elements. Good accuracy on Latin script.
🇷🇺 Russian (15.1s) — ❌ FAILED
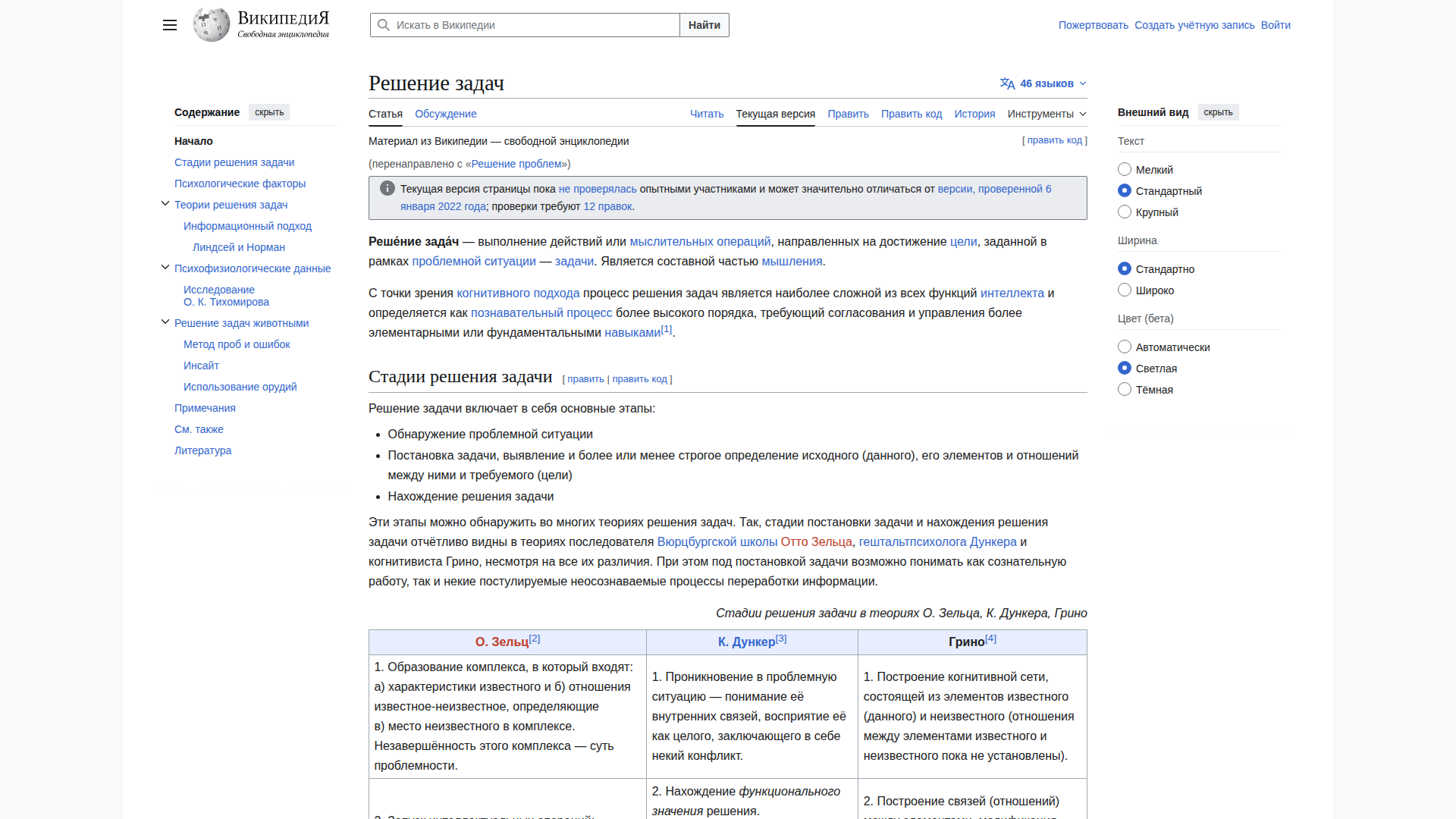
Model Response (1858 chars)
❌ Model hallucinated Korean text for a Russian page. Output: 검색 (Search), 목차 (Table of Contents), 서론 (Introduction) — all Korean. Zero Cyrillic text extracted. Identified language as Korean.
🇨🇳 Chinese (98.1s) — ⚠️ POOR
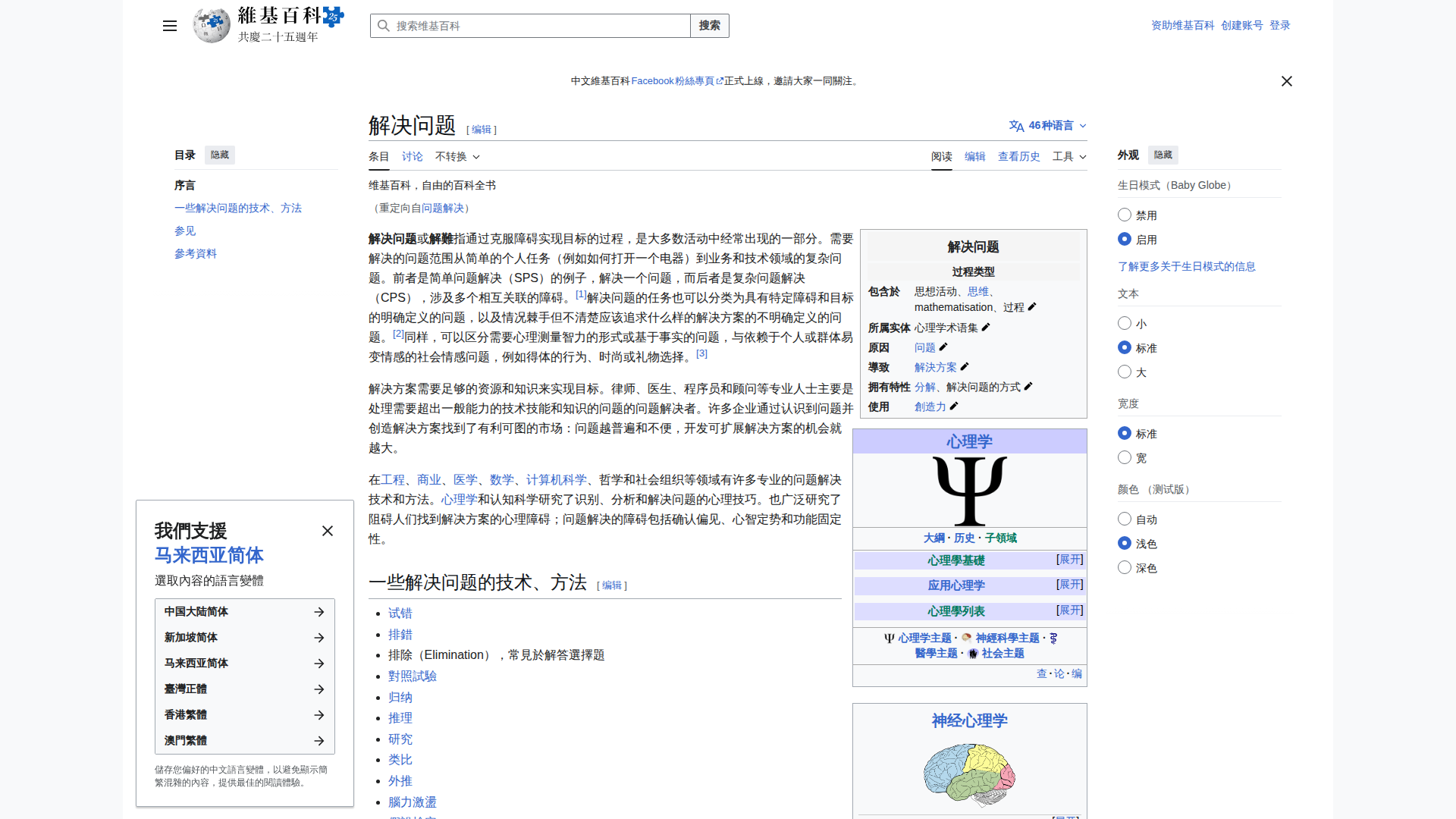
Model Response (6186 chars)
⚠️ Partial: 維基百科, 搜尋維基百科 correctly extracted. But article body is heavily hallucinated — fabricated sentences with real-looking Chinese characters that don't match the actual page content.
🇯🇵 Japanese (94.8s) — ❌ FAILED

Model Response (8326 chars)
❌ Correctly got ウィキペディア but then hallucinated Arabic characters "閏واق法" as the article title (repeated 13+ times). Mixed Japanese nav with Arabic body text — bizarre cross-script hallucination.
🇰🇷 Korean (98.4s) — ✅ BEST ASIAN
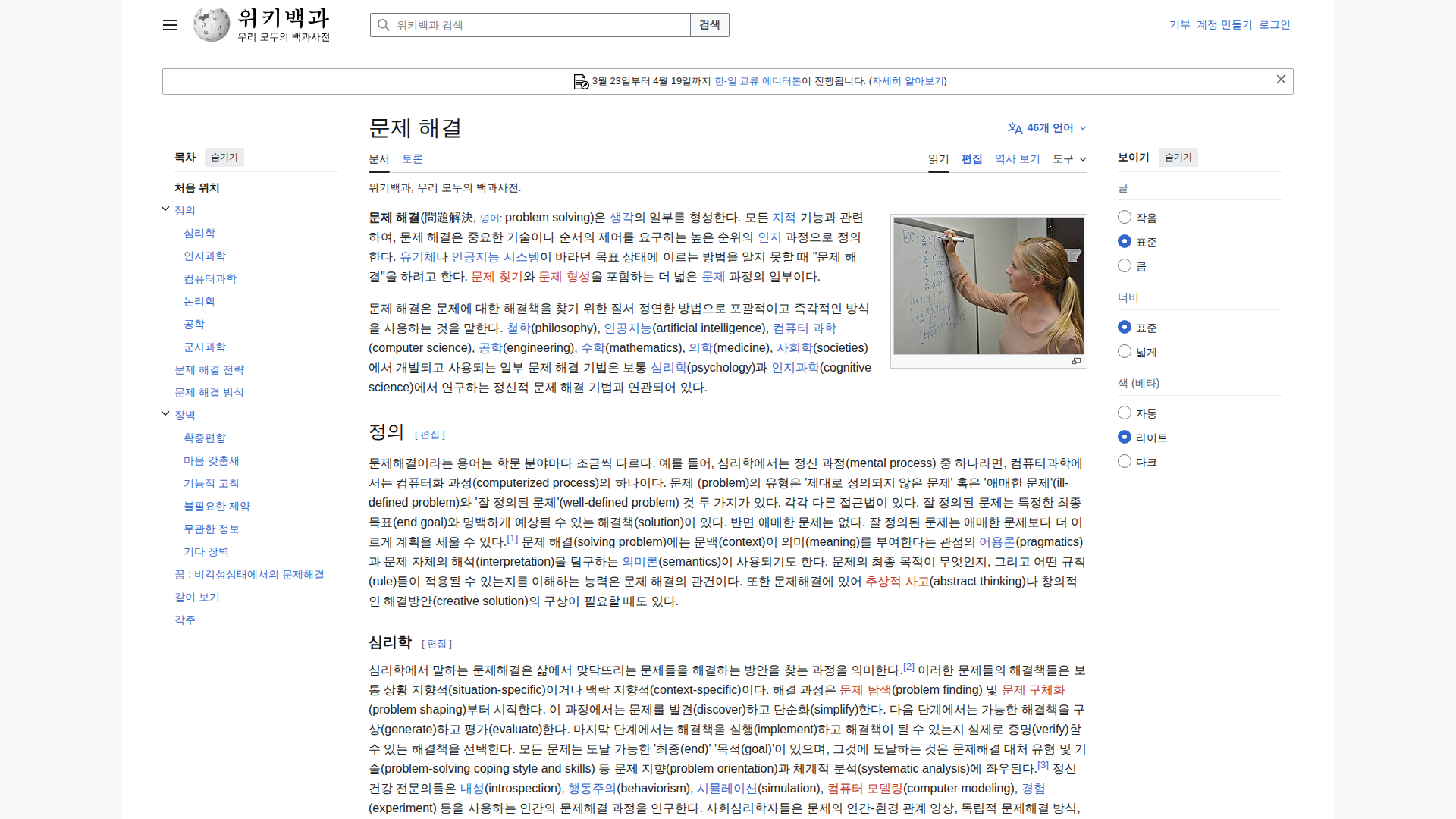
Model Response (9050 chars)
✅ Best Asian language result. Correctly: 위키백과, 문제 해결, 검색, 기부 계정 만들기 로그인. TOC sections partially correct. Banner text about editing period detected. Some garbled characters in body.
🇸🇦 Arabic (17.8s) — ⚠️ MODERATE
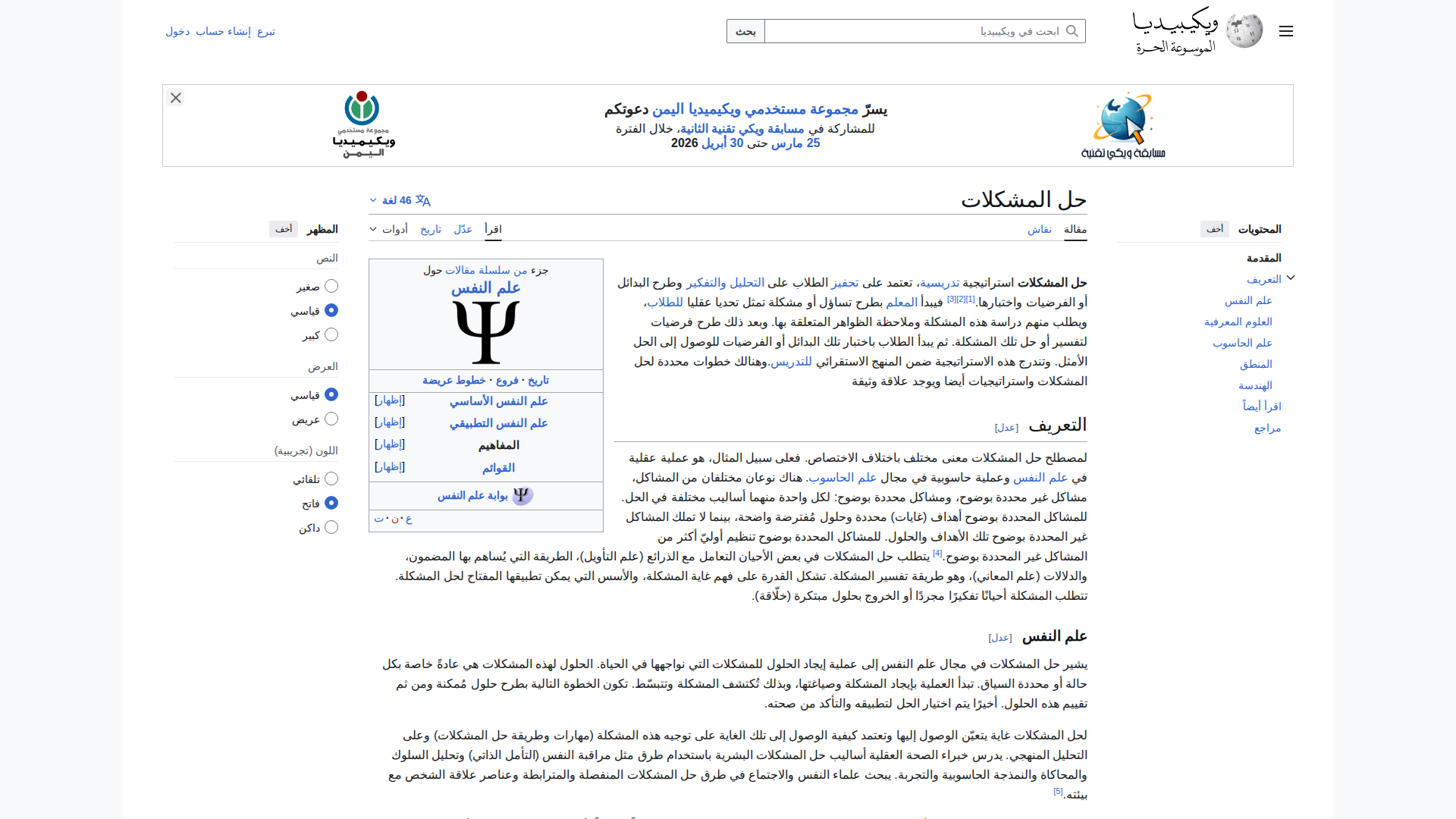
Model Response (2468 chars)
⚠️ Correctly identified Arabic and ويكيبيديا. Title: هل المشكلات (should be حل المشكلات — missed the ح). TOC sections correct: التعريف, علم النفس, العلوم المعرفية. Short response, RTL handling OK.
🇹🇭 Thai (98.2s) — ❌ FAILED
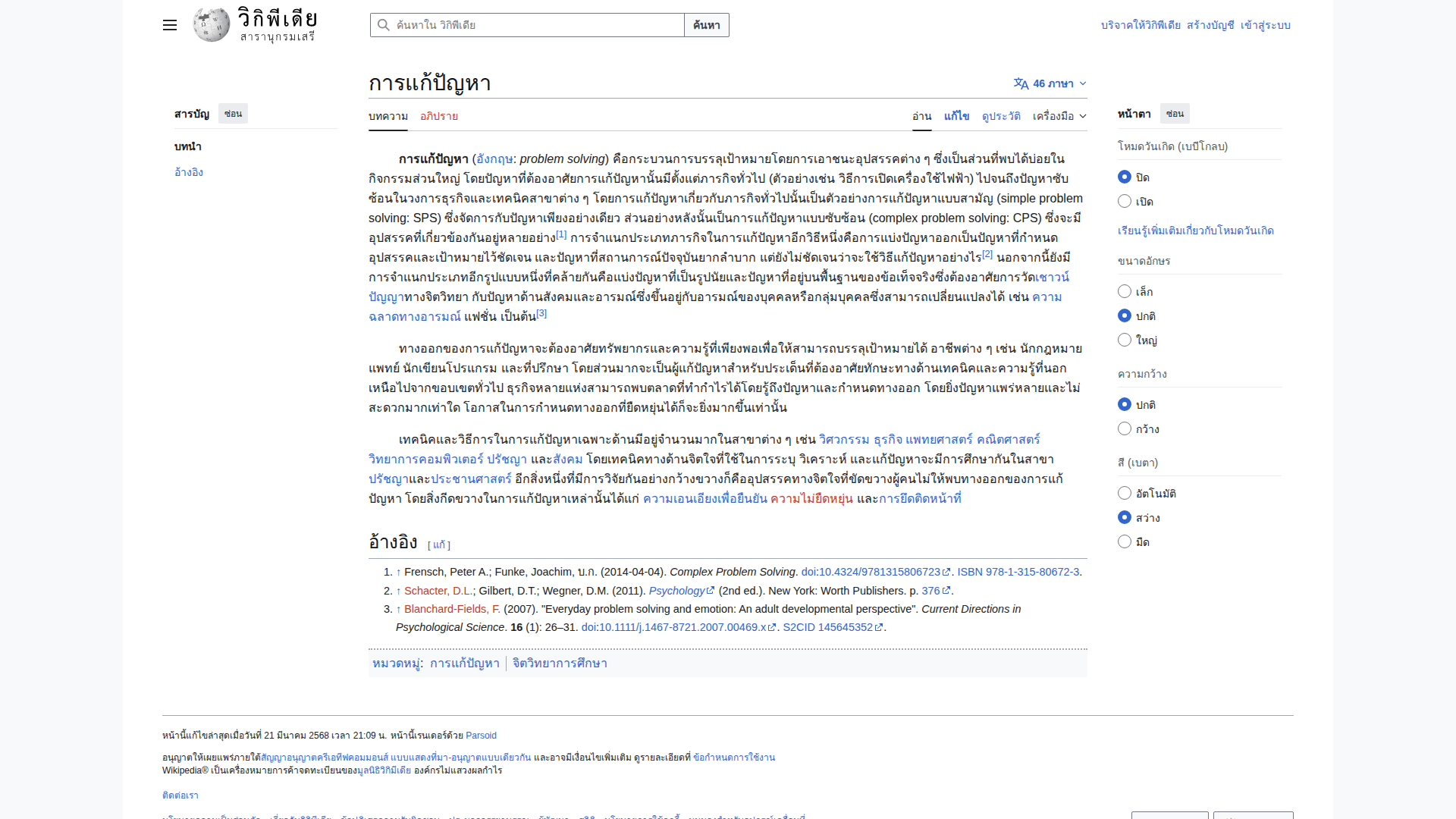
Model Response (8903 chars)
❌ Complete failure — entire response is in Korean (검색, 새 문서, 최근 변경, 도움말). Zero Thai characters extracted. Model seems to default to Korean when it can't read a script.
🇮🇳 Hindi (14.4s) — ❌ FAILED
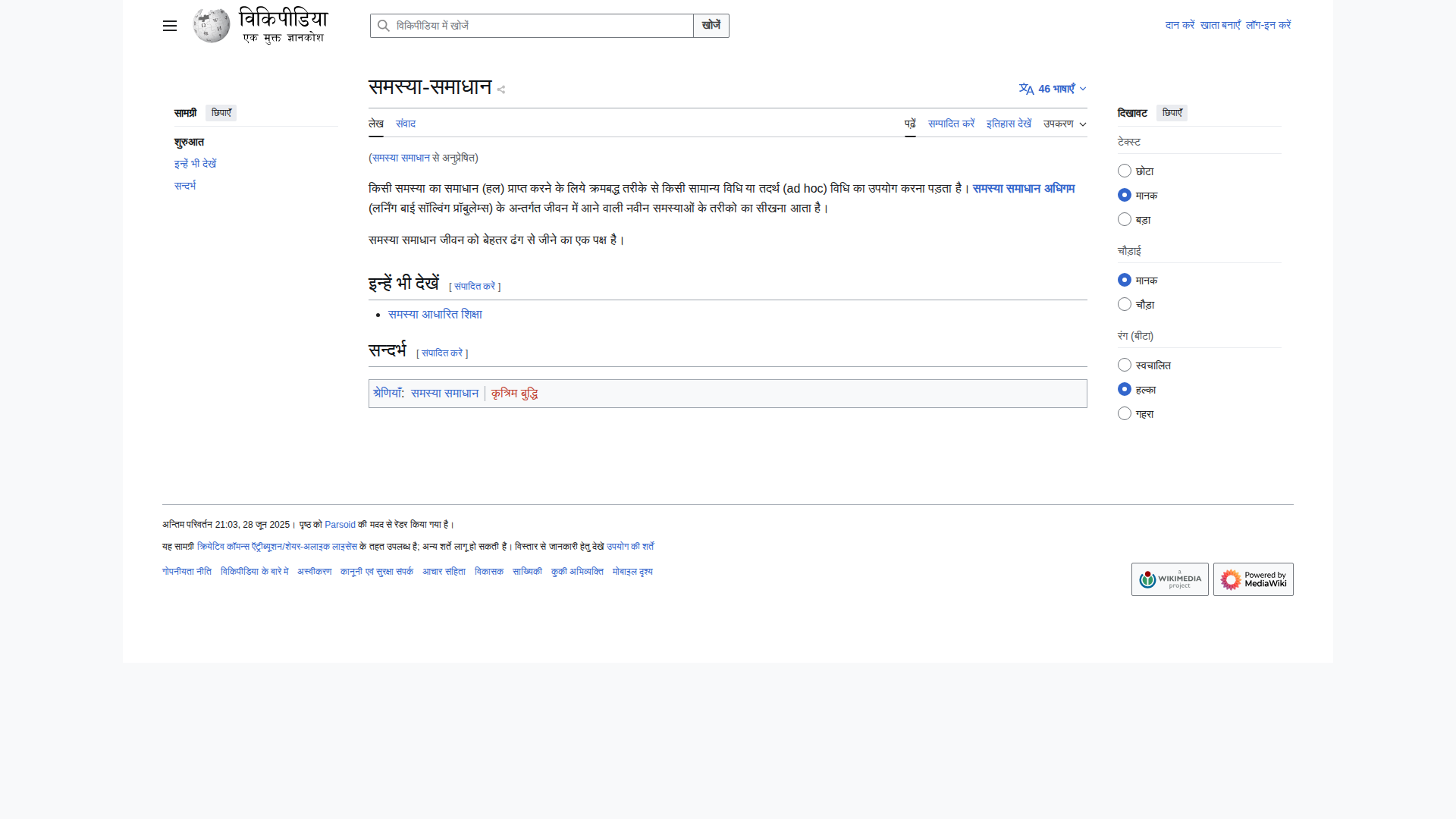
Model Response (1477 chars)
❌ Only विकिपीडिया extracted correctly (1 word). Rest: hallucinated Korean (검색, 찾으려면, 상상-상황). Identified as Korean language. Devanagari script almost completely unreadable to the model.
🇩🇪 German (31.2s) — ✅ GOOD
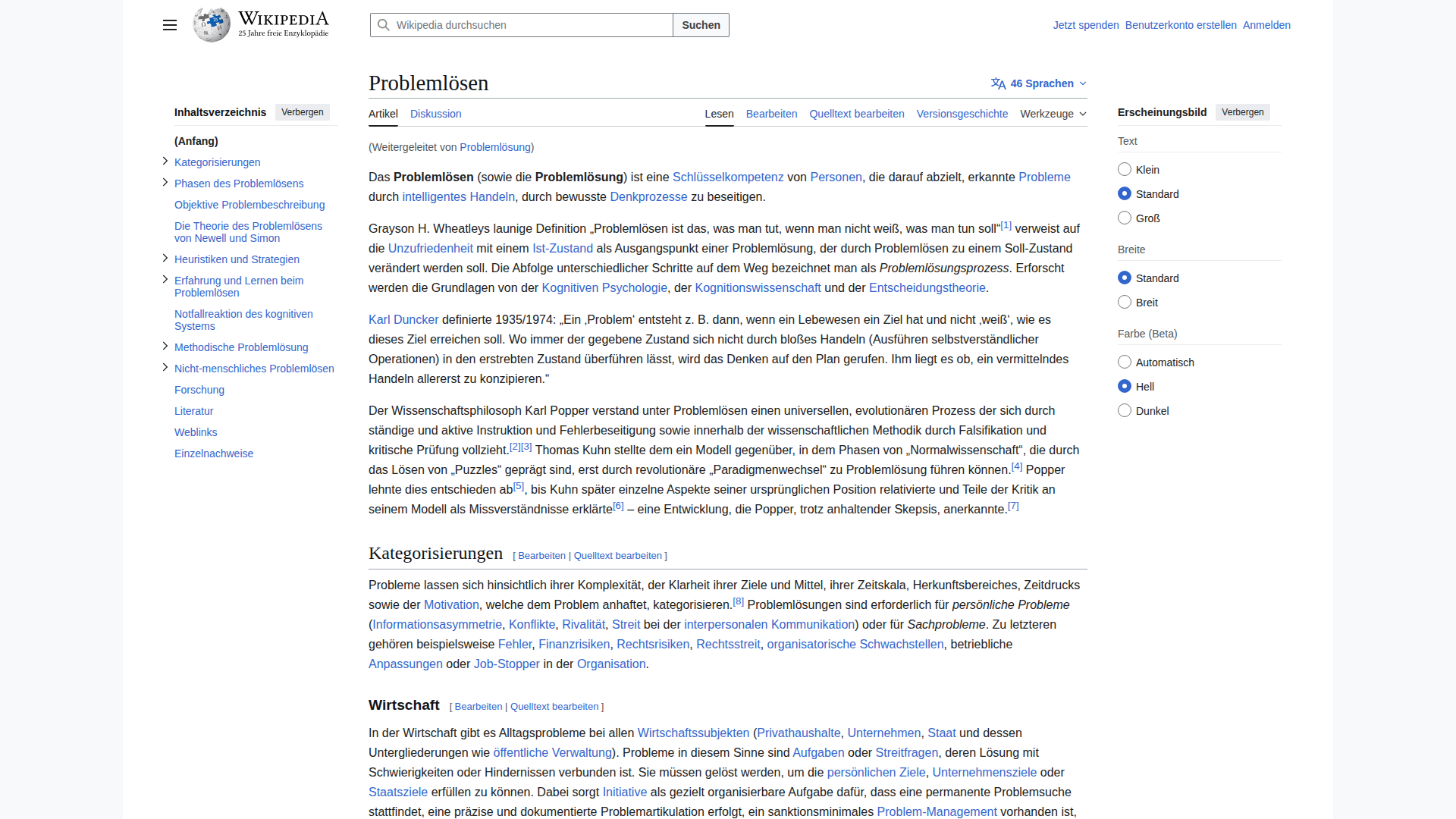
Model Response (5022 chars)
✅ Correct: "Problem lösen", Suchen, Jetzt spenden, Benutzerkonto erstellen, Anmelden. TOC and theorist names accurate. Minor: "Queltext" instead of "Quelltext" (one char). Umlauts handled correctly (ö, ü).
🇧🇷 Portuguese (22.3s) — ✅ GOOD
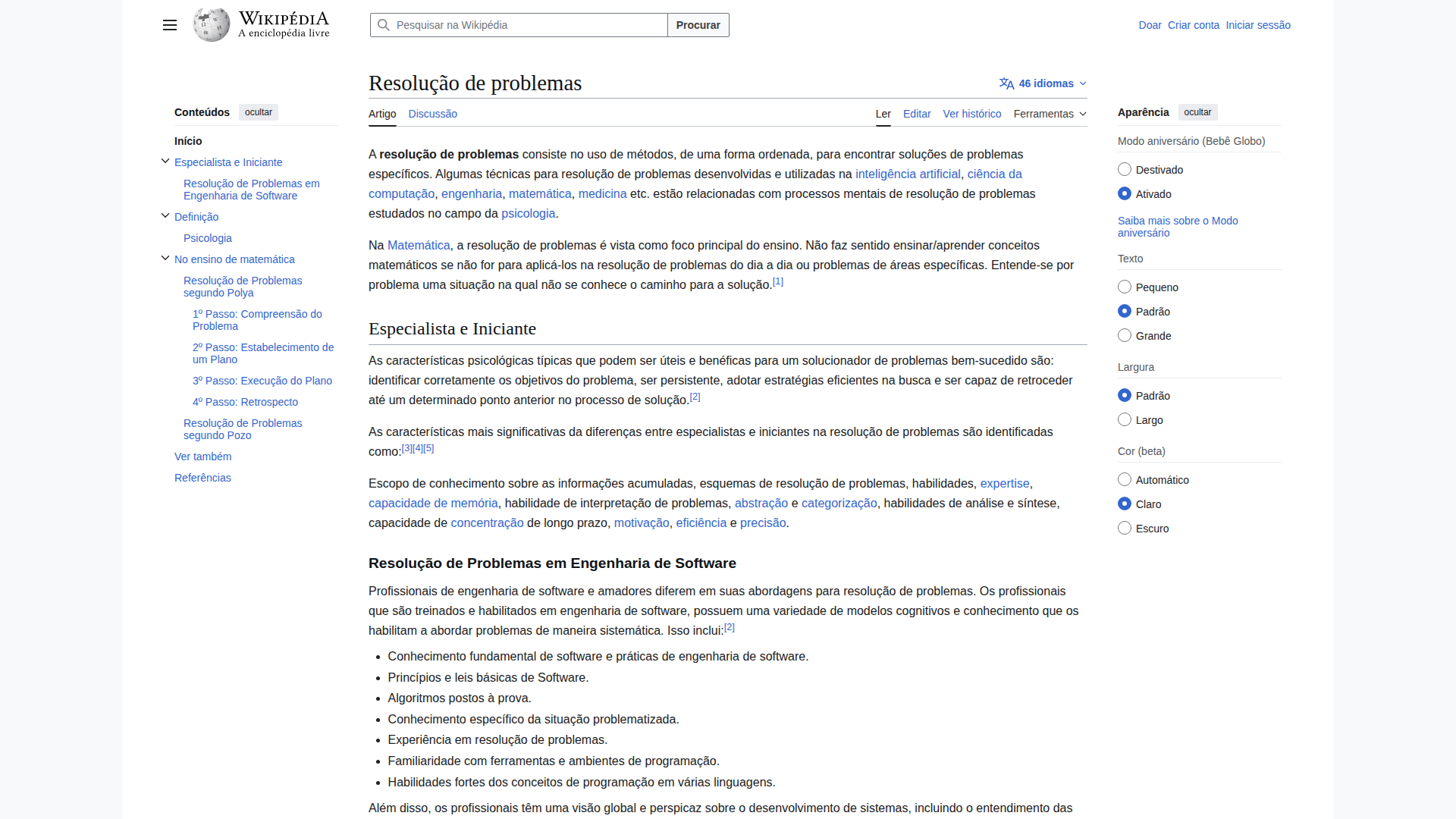
Model Response (3648 chars)
✅ Correct: "Resolução de problemas", Pesquisar na Wikipédia, Procurar, Doar, Criar conta, Iniciar sessão. Article intro accurately transcribed. Accented characters (ã, ç, é) handled correctly.
🔍 Analysis & Patterns
Script-based performance tiers:
✅ Tier 1 — Latin script (EN, DE, PT): Excellent. Accurate text extraction, correct language identification, proper handling of diacritics (ö, ü, ã, ç, é). Response times 22–98s.
⚠️ Tier 2 — Arabic script (AR): Moderate. Language correctly identified, RTL layout understood, most TOC items correct. Minor character errors (هل vs حل). Short responses suggest limited confidence.
⚠️ Tier 3 — CJK scripts (ZH, KO): Mixed. Korean best among Asian languages — correct language ID and key terms. Chinese partially correct headers but hallucinated body text.
❌ Tier 4 — Other scripts (RU, JA, TH, HI): Failed. Model defaults to Korean hallucinations when it cannot read the script. Russian (Cyrillic), Thai, and Hindi (Devanagari) are essentially unreadable. Japanese triggers bizarre Arabic hallucinations.
Key finding: The model has a strong Korean bias — when uncertain, it generates Korean text regardless of the actual script. This suggests the 4-bit quantization may have degraded multilingual OCR capabilities, particularly for non-Latin scripts. The model appears to have been fine-tuned or has stronger weights for Korean among Asian languages.
Response time pattern: Fast responses (14–22s) correlate with poor quality — the model "gives up" quickly on scripts it can't read. Long responses (94–98s) indicate the model is trying harder, hitting max_tokens.
🔬 DeepSeek-OCR-2 vs Gemma 4 E4B — Comparison Attempt
⚠️ DeepSeek-OCR-2-8bit: Failed to Produce Usable Output
We attempted to run mlx-community/DeepSeek-OCR-2-8bit on the same MacBook M1 Pro 16GB setup for comparison. After significant setup effort (upgrading from Python 3.9 to 3.13, installing mlx-vlm 0.4.4 + torch + torchvision, patching model modules), the model loaded but produced completely degenerate output — repetitive loops of questions like "What is the article about?" or "What are the interactive installations?" for all 10 languages.
Setup Challenges
1. Python 3.9 incompatibility: The system Python (Xcode 3.9) couldn't run mlx-vlm ≥0.3.x (needs scipy ≥1.15.3). Had to switch to Python 3.13 (/usr/local/bin).
2. Model architecture not supported: mlx-vlm 0.1.15 didn't have deepseekocr_2 module. Even after manual patching, BaseModelConfig was missing from old base.py.
3. Processor class mismatch: Model config references DeepseekVLV2Processor, not registered in transformers' AutoProcessor registry. The custom mlx-vlm-server.py couldn't load it.
4. Solution: Used the official mlx_vlm.server which handles model-specific processors internally. CLI generation worked (178 tokens/sec), but the server API produced garbage.
Comparison Table
| Language | Gemma 4 E4B (4-bit) | DeepSeek-OCR-2 (8-bit) | ||||
|---|---|---|---|---|---|---|
| Time | Lang ID | OCR Quality | Time | Lang ID | OCR Quality | |
| 🇺🇸 English | 98.5s | ✅ | ✅ Good | 31.4s | ❌ | ❌ Degenerate loop |
| 🇷🇺 Russian | 15.1s | ❌ Korean | ❌ Failed | 1.9s | ❌ | ❌ Empty |
| 🇨🇳 Chinese | 98.1s | ⚠️ Partial | ❌ Poor | 29.8s | ❌ | ❌ Degenerate loop |
| 🇯🇵 Japanese | 94.8s | ⚠️ Partial | ❌ Failed | 2.0s | ❌ | ❌ Empty |
| 🇰🇷 Korean | 98.4s | ✅ | ⚠️ Moderate | 29.8s | ❌ | ❌ Degenerate loop |
| 🇸🇦 Arabic | 17.8s | ✅ | ⚠️ Moderate | 29.8s | ❌ | ❌ Degenerate loop |
| 🇹🇭 Thai | 98.2s | ❌ Korean | ❌ Failed | 2.0s | ❌ | ❌ Empty |
| 🇮🇳 Hindi | 14.4s | ❌ Korean | ❌ Failed | 29.7s | ❌ | ❌ Degenerate loop |
| 🇩🇪 German | 31.2s | ✅ | ✅ Good | 29.9s | ❌ | ❌ Degenerate loop |
| 🇵🇹 Portuguese | 22.3s | ✅ | ✅ Good | 1.9s | ❌ | ❌ Empty |
Analysis
DeepSeek-OCR-2-8bit via mlx_vlm.server is non-functional for screenshot analysis.
The model generates two failure modes:
1. Degenerate loops (6/10 languages): Produces repetitive questions or phrases ("What is the article about?" ×500) until hitting max_tokens. Time: ~30s. These appear to be cases where the model sees the image but enters a self-referential loop.
2. Empty output (4/10 languages — RU, JA, TH, PT): Returns nothing in ~2s. Likely the model immediately produces an EOS token.
Root cause hypothesis: The mlx_vlm.server may not be correctly applying the DeepSeek-OCR-2 chat template or image preprocessing. The CLI tool (mlx_vlm.generate) works for text-only prompts (178 tokens/sec), suggesting the model weights are loaded correctly but the server's image handling is broken for this architecture.
Verdict: Gemma 4 E4B decisively wins this comparison — despite its own multilingual limitations, it at least produces structured, relevant output for Latin-script languages and partial output for Asian scripts. DeepSeek-OCR-2 via mlx-vlm server produces no usable output for any language.
📝 Conclusion
Gemma 4 E4B running via MLX on MacBook M1 Pro 16GB demonstrates excellent vision capabilities for screenshot analysis tasks:
✅ Reliability: All 3 test sites processed successfully with no infinite loops or generation failures — a critical improvement over Qwen2.5-VL which suffered from infinite loops on Wikipedia (122s timeout).
✅ Speed: Consistent 13–26s response times at 1920×1080 resolution. Average ~21s per screenshot — significantly faster than Qwen2.5-VL on complex pages.
✅ Scaling: Successfully processes images from 800×600 up to 17800×10013 (the limit is ~4.45MB base64 payload size, not resolution). All resolutions produced valid structured output.
⚠️ Accuracy: Some text transcription errors on small/dense text (e.g., misread URLs, garbled words on HN). Layout and context understanding is solid. GitHub repo names had minor OCR-style errors (e.g., "olama" instead of "ollama").
❌ Multilingual: Major weakness. Only Latin-script languages (EN, DE, PT) work reliably. Korean is the only well-supported Asian language. Cyrillic (Russian), Thai, Hindi (Devanagari) completely fail — the model hallucinates Korean text. Chinese and Japanese partially work but with heavy hallucination. Arabic is moderate. The 4-bit quantization likely degrades non-Latin script recognition significantly.
Verdict: For local vision model use on Apple Silicon, Gemma 4 E4B via MLX is excellent for Latin-script content — fast, stable, and capable of handling high-resolution screenshots. However, it is not suitable for multilingual OCR beyond Latin and Korean scripts. For CJK, Arabic, Cyrillic, Thai, or Devanagari content, a larger model or full-precision weights are recommended.